
A lot of plant managers are still running hydraulics on a bad pattern. The machine works until it doesn't. Then a hose bursts, a pump overheats, a filter blocks, or a valve starts sticking on a site that's awkward to reach and expensive to stop. By the time someone gets there with gauges, oil samples, and a laptop, the damage is already done and the day's plan has gone out of the window.
That approach costs more than the repair. It creates call-outs, idle operators, missed loads, delayed harvest work, disrupted production, and rushed parts orders. On mobile plant and agricultural equipment, it's worse because the fault often appears far from the workshop, with patchy signal and limited time to diagnose properly.
Remote monitoring systems change that. Used properly, they give you earlier warning of pressure instability, rising oil temperature, contamination, abnormal vibration, and other signs that a hydraulic system is drifting away from normal. The point isn't to flood your team with graphs. The point is to catch deterioration early enough to plan the job, protect the asset, and keep control of uptime.
From Reactive Repairs to Proactive Control
A typical failure begins subtly. An excavator on a remote contract starts running slightly hotter than usual. Cycle times lengthen a bit. The operator notices the machine feels lazy on first movement in the morning, but the job still gets done. A week later, the machine stops mid-task and now you're dealing with recovery, diagnosis, parts, labour, and the cost of a standing asset.
That's the difference between reactive maintenance and proactive control. Reactive maintenance asks, “What broke?” Proactive control asks, “What's changing, and how soon do we need to act?”
On the practical side, remote monitoring systems sit between those two questions. They watch the machine while it's working. They don't replace engineers, and they don't magically prevent every failure. What they do is give your team usable notice.
What changes on the ground
When a hydraulic system is monitored properly, the maintenance conversation improves fast:
- Pressure trends become visible: You can spot drift, instability, or repeated spikes before a component fails outright.
- Temperature stops being guesswork: Instead of relying on operator comments, you can see whether heat is linked to duty cycle, blockage, or cooling issues.
- Site visits become targeted: Engineers arrive with a reason for the visit, likely parts, and a shorter diagnostic path.
- Downtime becomes more predictable: Planned intervention is nearly always easier to absorb than an emergency stop.
A useful way to think about this is to separate monitoring from action layers. If you want a straightforward IT-side explanation of that distinction, the guide to remote monitoring and management software is a good reference. In plant terms, the same logic applies. Monitoring tells you what condition the asset is in. Management and maintenance workflows decide what to do next.
Practical rule: If the first sign of hydraulic trouble is a machine already down, you started looking too late.
For many operators, the best first step isn't a full digital overhaul. It's a condition-led programme on the most expensive or failure-prone assets. That's the same thinking behind condition-based maintenance for hydraulic systems. You focus on evidence, not calendar intervals alone.
There's also a wider operational reason this matters in the UK. Remote care and monitoring became part of mainstream service delivery during COVID, not a niche add-on. NHS Digital reported that 48.1% of GP appointments in England were conducted remotely in April 2020, up from 23.9% in April 2019, while total appointments fell to 24.3 million from 29.8 million over the same period, showing how quickly systems adapted to distributed service models (NHS remote consultation figures cited here). Industrial monitoring isn't the same as healthcare, but the lesson is similar. Once organisations see that remote visibility supports better decisions, adoption stops being theoretical.
What Is a Remote Monitoring System for Hydraulics
For hydraulics, a remote monitoring system is best thought of as a continuous health check for the machine or power unit. It watches the operating condition of the system while the asset is doing real work, then passes that information to the people who need to act on it.
A simple analogy helps. It's like a fitness tracker for machinery. A tracker doesn't repair your knee or improve your diet by itself. It records what's happening, flags poor patterns, and gives you enough information to do something before the problem gets worse.
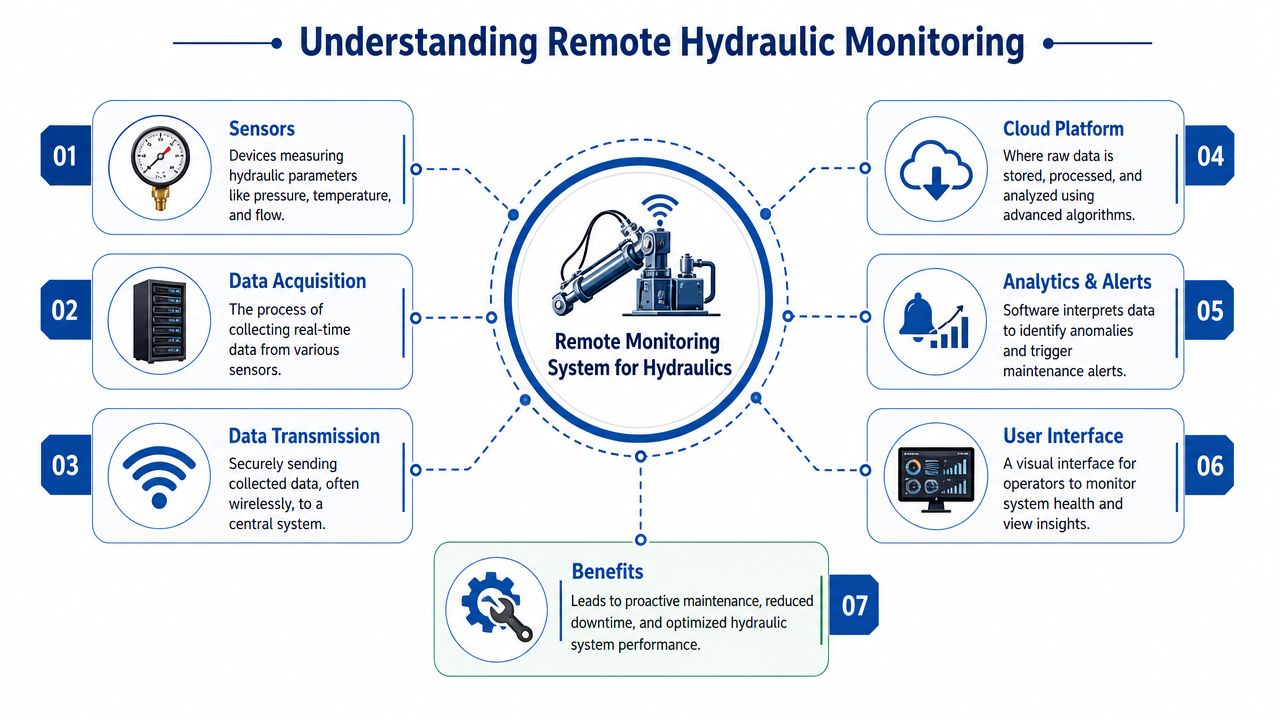
The four-part cycle
Most hydraulic remote monitoring systems follow the same working cycle.
-
Sense
Sensors measure live operating values such as pressure, oil temperature, flow, tank level, contamination, or vibration. -
Transmit
A gateway or telematics unit sends those readings off the machine. That might be over mobile data, site Wi-Fi, or another network suited to the location. -
Analyse
Software compares the live data with expected operating behaviour. It looks for drift, sudden changes, repeating faults, or combinations of symptoms that matter. -
Act
A maintenance manager, fitter, or service engineer uses the result to schedule inspection, adjust maintenance timing, or shut the asset down before damage spreads.
What it looks like in practice
On a hydraulic power pack, the system may monitor oil temperature and pressure stability through a production shift. On a telehandler or sprayer, it may focus on pressure peaks, return-line temperature, and filter condition while the machine is moving between locations. On a fleet, it gives you a way to compare assets and identify which one is starting to behave differently from the rest.
The best systems don't just collect data. They help you decide whether to ignore, inspect, or intervene.
That distinction matters because many buyers confuse remote monitoring with camera viewing, GPS tracking, or general machine telematics. Those tools can complement each other, but they aren't the same thing. If you want a plain-language example of how remote viewing works in another hardware category, this Magic Eagle camera monitoring guide is a useful comparison. Hydraulics monitoring goes further into machine condition and fault development, not just visibility.
What it is not
A remote monitoring system for hydraulics isn't:
- A substitute for proper commissioning: Bad pipe sizing, poor filtration, wrong relief settings, and heat issues still need engineering correction.
- A cure for neglected maintenance: Dirty oil, worn couplings, and ignored leaks will still become failures.
- A dashboard for dashboard's sake: If nobody owns the alerts, the system becomes expensive wallpaper.
The value comes when the monitored point matches a failure mode you care about.
The Key Hardware Components You Need to Know
The hardware side is where many projects either become dependable and useful, or awkward and unreliable. For hydraulics, the core building blocks are simple enough: sensors, a gateway, and a telemetry method. The hard part is choosing components that suit the machine, the environment, and the maintenance decision you want to make.
Sensors that earn their place
Not every machine needs every sensor. Start with the fault modes that cause real cost.
For hydraulic systems, the usual candidates are:
- Pressure sensors: Good for spotting drift, transients, blocked lines, relief valve problems, and pump wear.
- Temperature sensors: Useful on reservoirs, return lines, and cooler circuits where heat tells you a lot about efficiency and system stress.
- Flow sensors: Best where flow loss would show internal leakage, poor pump performance, or control issues.
- Vibration sensors: Helpful on pump and motor assemblies where bearing or alignment problems show up mechanically before they become hydraulic failures.
- Fluid condition sensors: These can track contamination, moisture, or oil quality trends, which is valuable on critical systems and long-life assets.
The mistake is fitting sensors because they're available, not because they answer a real maintenance question. If a signal won't change a decision, it probably doesn't need to be monitored remotely.
Gateways and local data handling
The gateway is the machine-side collection point. It gathers readings from the sensors, timestamps them, and sends them onward. On mobile plant, this unit needs to cope with vibration, power variation, dust, moisture, and awkward installation spaces.
A decent gateway should do three things well:
- Read industrial signals cleanly: Common sensor outputs need to be handled reliably.
- Store data during connection loss: Remote sites don't always have stable coverage.
- Support secure communications: If the gateway is weak, the whole system is weak.
For fixed plant, installation is often easier because power and enclosure space are less constrained. On mobile assets, packaging matters more than spec sheets suggest.
A practical temperature trend on a cooler return line often gives more maintenance value than a long list of marginal signals. For assets where heat management is critical, hydraulic temperature monitoring is one of the highest-value starting points.
Choosing telemetry for UK sites
Telemetry choice affects running cost, reliability, and how often people trust the system. The right answer depends on where the machine works and what volume of data you need.
| Technology | Coverage | Data Cost | Best For |
|---|---|---|---|
| Cellular 4G or 5G | Good in many urban, roadside, and populated working areas, but variable on remote land and inside some industrial buildings | Usually moderate and straightforward to manage | Mobile plant, hire fleets, service vehicles, and mixed-location assets |
| Satellite | Broad reach in isolated areas where terrestrial coverage is poor | Usually the highest ongoing cost | Remote agricultural land, upland sites, and isolated infrastructure |
| Wi-Fi or LoRaWAN | Strong where you control the site network, limited beyond that footprint | Often low once infrastructure is in place | Fixed industrial plant, yards, factories, and estates with managed network coverage |
What works and what doesn't
What works is a modest hardware stack tied to a known failure mechanism. What doesn't work is fitting sensors to everything, sending too much data, and assuming the platform will somehow create value on its own.
If your machine works in mud, washdown, vibration, and shock, buy hardware for that reality, not for a clean demo bench.
For UK operators, the site matters as much as the machine. A combine running over large acreage, a loader moving between farms, and a power pack in a manufacturing cell don't need the same telemetry design. Treat communication as an engineering choice, not an afterthought.
From Raw Data to Actionable Maintenance Alerts
The software layer decides whether the system becomes useful or irritating. Anyone can collect values. The hard part is turning raw readings into an alert that a maintenance team can trust.

A good remote monitoring system doesn't shout every time a signal moves. Hydraulic systems are dynamic by nature. Pressure rises and falls. Temperature changes with ambient conditions, workload, and oil age. Operators use machines differently. If the software treats every fluctuation as a fault, your team stops listening.
Smart alerts beat simple thresholds
The better approach is to combine thresholds with context and trend logic.
A single high temperature event may not mean much on a hot day under heavy load. A slow but steady rise in normal operating temperature over several shifts is often more valuable. The same applies to pressure behaviour. One short spike may be normal. Repeated pressure instability during the same duty phase is worth investigating.
Useful alert rules often look like this:
- Trend-based triggers: Rising temperature, worsening contamination, or growing vibration over time.
- Operating-state triggers: Alerts only when the machine is under load, at working speed, or in a specific function.
- Combined-condition triggers: A warning appears only when two or more symptoms line up, such as heat plus pressure loss.
- Persistence rules: The system waits for the condition to persist before raising a task.
This is how you reduce false alarms without hiding real risk.
Dashboards that help managers decide
A maintenance manager rarely needs every live number on the front screen. What helps is a clear machine health view. Green if the asset is operating within normal range. Amber if deterioration is developing. Red if intervention is needed.
The dashboard should let you move down a level when needed:
- Fleet or site overview first
- Machine-specific status second
- Detailed trend and event history third
That structure matters because people make different decisions at each level. A supervisor wants to know what needs attention this week. A fitter wants the signal history before heading to site.
Later in the process, a short technical explainer like this can help teams align around what modern monitoring platforms are doing behind the scenes:
Why workflow matters more than visual polish
A polished dashboard with poor escalation logic is a nuisance. A plain dashboard with sensible alerts is worth having. That's especially true in UK operations where engineering coverage is stretched and response time matters.
The broader backdrop is hard to ignore. The NHS Long Term Workforce Plan projects a need for around 360,000 to 460,000 more staff by 2036/37, which is one reason UK discussions about remote monitoring increasingly focus on workload reduction, integration, and avoiding alert fatigue rather than vague benefit claims (workforce projection discussed here). Industrial maintenance teams face the same practical question. Does the system reduce effort, or does it create another screen someone has to babysit?
Plain dashboards are fine. Unclear ownership of alerts is not.
If an alarm doesn't lead to a named action, it isn't maintenance intelligence. It's noise.
Integrating Monitoring with Your Existing SCADA and CMMS
A remote monitoring system shouldn't sit off to one side like a separate hobby project. If the data stays trapped in its own portal, people stop checking it, duplicate admin creeps in, and the promised efficiency never lands.
The strongest setups connect remote monitoring to the tools you already use for operations and maintenance. For fixed plant, that usually means SCADA. For engineering workflow, it usually means a CMMS.
SCADA integration on industrial plant
On a production site, hydraulic condition data becomes more useful when it appears alongside other process information. A power unit's oil temperature means more when you can compare it with line demand, machine state, shift pattern, or ambient conditions.
That's why SCADA integration works well on fixed assets such as:
- Hydraulic power packs feeding production equipment
- Press systems
- Material handling lines
- Plant with centralised utilities
In those cases, operators can see hydraulic health as part of the wider operating picture, not as an isolated maintenance feed.
CMMS integration for real maintenance work
CMMS integration is often where the return becomes practical. An alert stops being a warning on a screen and becomes a task with ownership.
A sensible flow looks like this:
- A monitored parameter crosses a meaningful rule.
- The platform classifies the issue by severity.
- The CMMS generates or suggests a work order.
- The engineer receives the task with asset, fault type, and supporting trend data.
- The job is closed with findings that improve future alert settings.
That process is far better than relying on someone to notice an alarm and remember to type up a job later.
A lot of maintenance teams already have the foundations for this through their preventive maintenance plans. Remote monitoring adds condition evidence to that structure. It doesn't replace planning. It sharpens it.
Avoiding the silo trap
Problems start when integration is treated as optional. Then you get two lists of work, two records for the same asset, and no clean history linking alert to intervention.
Keep the integration standard simple:
- One asset ID: The monitored asset must match the maintenance asset.
- One ownership path: Every critical alert needs a responsible person or team.
- One history trail: Engineers should be able to see the trend, the work order, and the outcome together.
For managers, remote monitoring systems transition from being interesting technology to becoming part of normal maintenance control.
A Practical Guide to Selecting Your System
Buying the wrong system usually happens for one of two reasons. Either the buyer chases features instead of failure modes, or they underestimate security and support. In both cases, the kit may work in a demo and disappoint in the field.

Start with the machine, not the brochure
The first question isn't “Which platform is best?” It's “Which machine problem are we trying to catch earlier?”
That answer shapes everything else. A fixed hydraulic power unit in a factory may justify richer connectivity and tighter SCADA integration. A trailer-mounted power pack or mobile agricultural machine may need a simpler, tougher package with low-power telemetry and fewer measured points.
Use this shortlist when comparing suppliers:
- Ruggedness: Enclosures, connectors, cable routing, vibration resistance, and environmental protection need to suit oil, dirt, water, washdown, and impact.
- Compatibility: The platform should read the sensor types and machine signals you use.
- Scalability: One pilot asset is easy. A fleet rollout is where weak systems get exposed.
- Usability: If the dashboard takes specialist training to interpret basic health status, adoption will suffer.
- Support quality: You want real technical support during setup, fault finding, and rule tuning.
Security isn't optional
This needs plain speaking. If you're exposing machine data from operational assets, security is part of the engineering decision.
The UK risk background is serious enough to treat this as essential. The 2025 UK Government cyber survey found that 50% of businesses and 45% of charities experienced some form of cybersecurity breach or attack in the previous 12 months, a reminder that any connected monitoring estate needs secure-by-design architecture (UK cyber risk context cited here). For industrial and agricultural operators, that means thinking beyond convenience.
Ask suppliers direct questions about:
- Encryption: How is data protected in transit and at rest?
- Authentication: Who can access dashboards, alerts, and device settings?
- Segmentation: Can the monitoring path be separated from more sensitive operational networks?
- Patch management: How are gateway firmware and platform vulnerabilities handled?
- Access control: Can permissions be limited by role, site, or asset group?
Buy on security before you buy on screen design.
The hidden selection factor
Digital access still matters, especially if your teams, subcontractors, or customers need to receive and act on remote data in the field. Ofcom reported that 96% of UK adults were online in 2024, but that still leaves an offline minority, with lower take-up among older adults and lower-income groups, which is why UK guidance continues to treat digital inclusion as a practical deployment issue rather than a solved one (digital inclusion context discussed here). In industrial terms, the lesson is simple. Don't assume every operator, driver, or site contact will use an app comfortably.
So when selecting a system, check whether alerts can be delivered and acted on in more than one way. Browser access, email summaries, role-based dashboards, and service-team escalation options often matter more than flashy mobile features.
A practical buyer usually wins by choosing the system that is easiest to deploy consistently, easiest to secure, and easiest for the maintenance team to trust.
Implementation and Proving the Return on Investment
Most successful projects start small. One machine. One recurring issue. One set of alert rules. That approach shows you quickly whether the monitoring point is useful, whether the data arrives reliably, and whether your team will act on it.
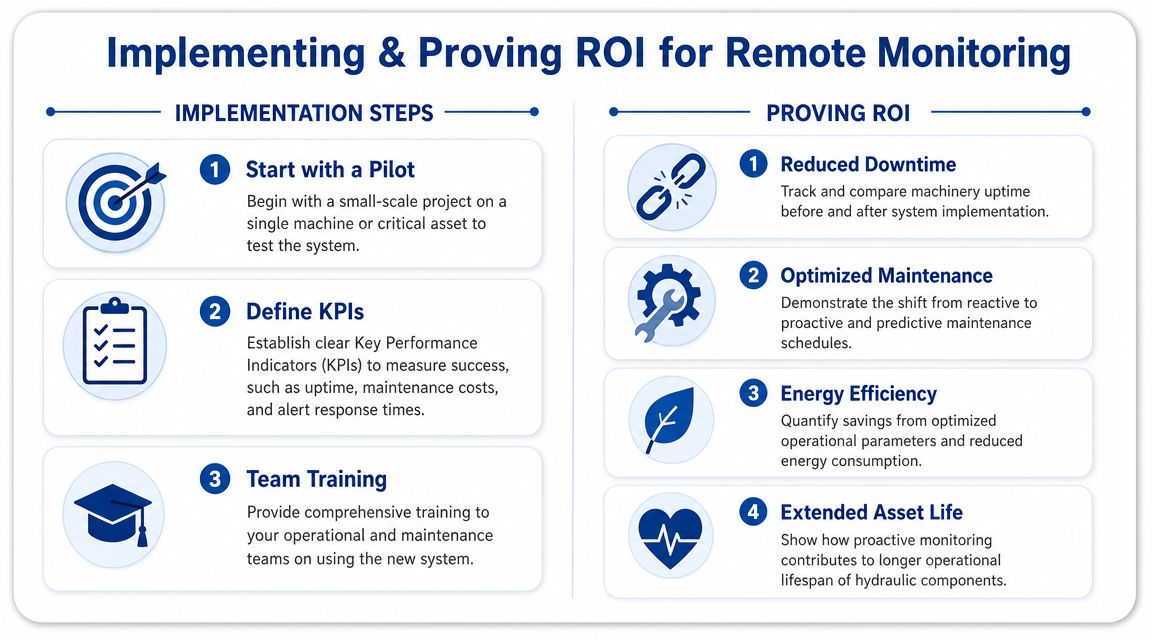
A sensible rollout path
A practical implementation sequence is usually:
- Pick a critical asset: Choose the machine whose failure hurts most, not the easiest one to instrument.
- Define the failure mode: Be specific. Pressure instability, overheating, contamination, or abnormal vibration.
- Set action rules: Decide who gets the alert and what response is expected.
- Train the users: Operators, fitters, and managers need the same understanding of what amber and red mean.
- Review and tune: Early thresholds are rarely perfect. Adjust them after real operating data comes in.
That discipline matters more than trying to install a complete fleet solution in one go.
ROI example one, avoided downtime
The cleanest return often comes from avoided downtime. Think about a machine that earns its keep daily and sits on a remote or high-value job. If a monitoring alert shows worsening heat and pressure behaviour early enough for you to service the cooler, change a blocked element, or inspect a pump during planned downtime, you've avoided the far bigger cost of a stopped job.
You don't need a complex finance model to prove that. Compare:
- the annual monitoring cost for that asset
- the cost of one emergency recovery or urgent site call-out
- the labour and plant standing time during an unplanned stoppage
- the knock-on effect on production, harvest, or contract timing
On many sites, one prevented breakdown pays for a lot of monitoring.
ROI example two, planned repair versus major failure
Hydraulic failures rarely stay neatly contained. A worn seal, dirty oil issue, or developing pump fault can turn into a broader strip-down if it's missed. The financial logic is simple even without forcing a generic formula. A planned repair usually means controlled labour, standard parts ordering, and less collateral damage. A catastrophic failure often means contamination spread, extra flushing, secondary component damage, and longer outage.
That's why trend data matters. If the system shows deterioration rather than a sudden cliff-edge event, you can intervene at the cheaper stage.
Planned repairs are bought with information. Emergency repairs are bought with disruption.
ROI example three, operating efficiency
Monitoring also helps when the machine is still working but not working well. Hydraulic systems that run hotter than they should, operate outside their intended pressure behaviour, or cycle inefficiently can waste energy and stress components unnecessarily. On mobile plant, that can show up as higher fuel use. On fixed equipment, it may show up as excess heat load, slower response, or shortened oil life.
You won't prove that return from one day of data. You prove it by comparing operating behaviour before and after corrective action. Once teams see that a pressure setting, cooling issue, or component wear pattern has a measurable operating effect, monitoring becomes a management tool rather than an expense line.
What good proof looks like
If you want board-level confidence, keep the evidence simple and operational:
- Uptime records: Fewer unplanned stops on monitored assets
- Maintenance history: More planned interventions, fewer emergency jobs
- Repair scope: Earlier fixes with less secondary damage
- Asset behaviour: More stable temperature, pressure, or contamination trends over time
That's enough to build a credible case for wider rollout.
If you want practical advice on hydraulic monitoring, component selection, or a more proactive maintenance approach for mobile and industrial equipment, speak to MA Hydraulics Ltd. Phone 01724 279508 today, or send a message to the team.
