
A hydraulic machine rarely gives you a convenient failure window. It runs through a busy shift, starts to feel a bit sluggish, gets a little hotter than usual, and then stops when production needs it most. In a factory, that can mean a dead press, a stalled conveyor circuit, or a power pack that suddenly won't hold pressure. On mobile plant, it can mean lost hours in the yard or a machine stranded on site waiting for diagnosis.
That pattern is why so many maintenance teams want to move beyond firefighting. Reactive repair is expensive in labour, parts, disruption, and frustration. Rigid calendar servicing isn't much better when it forces strip-downs that weren't needed, while still missing faults that developed between service intervals.
Condition based maintenance offers a more practical route. Instead of servicing hydraulics because the calendar says so, you maintain them because the equipment is showing measurable signs of deterioration.
What Is Condition Based Maintenance and Why It Matters for Hydraulics
Condition based maintenance is a maintenance strategy that triggers work when monitored asset condition shows deterioration, not only because a service interval has elapsed. In UK practice, it gained momentum alongside wider digital asset management thinking after the publication of ISO 55000 in 2014, which gave asset-intensive organisations a stronger framework for disciplined data, risk prioritisation, and lifecycle decisions, as outlined in IBM's overview of condition based maintenance.
For hydraulic systems, that distinction matters. A pump doesn't care what month it is. A directional valve doesn't fail because the planner's spreadsheet reached a date cell. Hydraulic components fail because contamination rises, temperature drifts, pressure becomes unstable, seals degrade, or rotating elements begin to wear.
Why hydraulics suit this approach
Hydraulic equipment is full of failure modes that usually leave clues before complete failure. Those clues are often measurable:
- Oil condition changes when contamination starts circulating.
- Temperature drifts when friction or internal leakage increases.
- Pressure becomes unstable when pumps, relief valves, or filters start struggling.
- Vibration changes when rotating assemblies loosen or wear.
That's why condition based maintenance sits in a useful middle ground. It's more intelligent than fixed-interval preventive maintenance, but it doesn't require every site to leap straight into a fully mature predictive model.
Practical rule: If a hydraulic fault gives a measurable warning before shutdown, it's a candidate for condition based maintenance.
What good practice looks like
A good CBM programme doesn't begin with buying sensors. It starts with deciding what asset condition matters, what failure modes are worth catching, and what action should follow when a threshold is crossed.
On a hydraulic press, that might mean watching oil cleanliness, return-line filter differential pressure, and pump vibration. On a mobile power pack, it might mean temperature stability, pressure performance, and signs of leakage. On many sites, it sits alongside planned servicing rather than replacing it outright. If you already run preventive maintenance plans for hydraulic assets, CBM sharpens them by telling you where fixed intervals still make sense and where condition should take the lead.
Why it matters in real operations
The biggest gain isn't only fewer breakdowns. It's better timing. Teams can inspect before a pump scores its internals, change a filter before bypass becomes a contamination event, or investigate rising heat before seals harden and leakage escalates.
Hydraulics reward that kind of discipline. When you catch a problem early, the repair is often smaller, cleaner, and easier to plan. When you miss it, the same fault tends to spread through oil, filtration, valves, actuators, and downtime.
Laying the Foundations Identifying Critical Failures and Assets
Most failed CBM projects start the same way. Someone decides to monitor everything, buys a mix of hardware, and then gets buried in data that doesn't drive any decision. The better approach is narrower and more useful. Start with the hydraulic assets that hurt the business most when they fail.
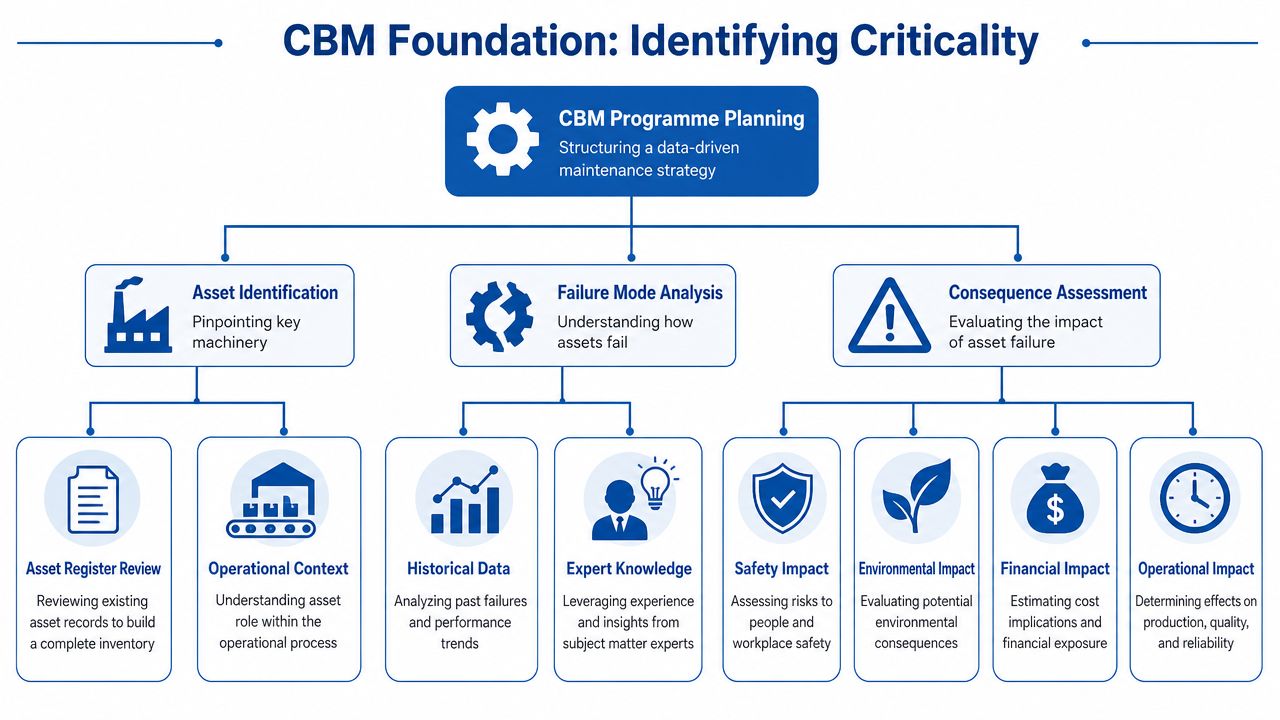
Where to start first
Pick assets using consequence, not annoyance. The machine that fails most often isn't always the machine that matters most. A small hydraulic unit that stops one key process can be more critical than several nuisance faults elsewhere.
Use a simple screen:
| Question | What to ask |
|---|---|
| Operational impact | Does failure stop production, loading, lifting, or movement? |
| Safety exposure | Could loss of pressure, uncontrolled movement, or hose failure create risk? |
| Repair difficulty | Is the component accessible, standard, or awkward and slow to replace? |
| Failure visibility | Does the fault give a measurable warning such as heat, vibration, pressure drift, or contamination? |
If the answer is “high consequence” and “clear warning signs”, that asset is usually a strong CBM candidate.
When CBM is cheaper than preventive maintenance
This is the part buyers often want answered plainly. CBM isn't automatically better for every hydraulic asset. It's most defensible when the cost of unplanned failure is high enough to justify monitoring overhead, and when the failure mode produces measurable precursor signals. Industry guidance also reports that predictive and condition-based approaches can reduce maintenance costs by around 25% to 30% and cut unplanned downtime by about 35% to 45% when properly applied, according to Tractian's condition based maintenance guidance.
That means the economics favour CBM on assets such as:
- Critical hydraulic power packs that stop a line or machine group
- Mobile plant hydraulics where site breakdowns create long delays and callout costs
- Systems exposed to contamination risk where damage spreads quickly
- Pumps and valve groups with a history of wear that can be detected before total failure
CBM is less attractive on low-impact assets with random failure patterns and no practical measurement route.
Don't ask, “Can we monitor this?” Ask, “Will monitoring this change what we do in time to matter?”
Map the failure mode before you buy the sensor
For hydraulics, the planning step should connect failure mode to early indicator. That sounds obvious, but it's where many programmes go wrong.
A few examples:
- Pump cavitation or wear often shows up through vibration change, pressure instability, and temperature rise.
- Contamination-driven valve wear can be tracked through oil cleanliness and filter behaviour.
- Blocked filtration often appears as rising differential pressure across the filter.
- Overheating points towards cooling issues, internal leakage, incorrect settings, or excessive duty.
Once that chain is clear, the monitoring plan becomes much simpler. You're no longer collecting data because it's available. You're collecting it because a known failure mode moves that variable first.
Choosing Your Monitoring Toolkit for Hydraulic Systems
Hydraulic CBM works best when the toolkit matches the failure mode. Not every machine needs every sensor, and not every sensor belongs online full-time. The aim is to pick the few measurements that give a clear signal early enough to act.

Four tools that do most of the work
| Monitoring method | Best for | What it tells you | Common limitation |
|---|---|---|---|
| Vibration analysis | Pumps, motors, rotating drives | Wear, looseness, cavitation, imbalance | Interpretation matters |
| Oil analysis | Reservoirs, return lines, critical circuits | Cleanliness, contamination, wear indication | Sampling discipline matters |
| Temperature monitoring | Power packs, pumps, manifolds, coolers | Friction, overload, cooling problems | Heat is useful, but not always specific |
| Pressure monitoring | Pumps, filters, actuators, valve circuits | Blockage, leakage, instability, underperformance | Load variation can create false alarms |
Vibration and acoustics on rotating assets
If a hydraulic pump or motor is degrading mechanically, vibration is often one of the earliest useful indicators. It's especially valuable where bearings, couplings, mounting looseness, or cavitation are involved. The trick is to trend change from a known healthy baseline rather than reacting to one isolated reading.
Some teams also combine vibration with listening methods in the early stages of fault finding. For sites looking at non-invasive screening, acoustic monitoring for machinery condition can be a practical complement on selected assets.
Later in the decision process, lubrication quality often comes into the conversation for pump drives and related rotating components. For engineers reviewing lubrication behaviour in precision applications, these SEA insights on kluber NBU 15 are useful background because they highlight the sort of compatibility and duty considerations that can influence wear patterns and signal interpretation.
Oil and contamination monitoring
For hydraulics, contamination control is usually the highest-value starting point. If the oil is dirty, the rest of the system suffers. Valves stick, pump surfaces wear, seals deteriorate, and the machine becomes harder to diagnose because the contamination creates multiple secondary faults.
Use oil monitoring where contamination risk is real and consequences are high. That can include:
- Reservoir sampling points for periodic checks
- Return-line monitoring on critical units
- Filter differential pressure checks to catch restriction or bypass risk
- Water ingress checks on outdoor and mobile equipment
Temperature and pressure in context
Temperature is one of the easiest measurements to collect, but it only becomes useful when it's tied to operating state. A hot-running power pack under heavy duty might be normal. The same temperature on a lightly loaded machine might indicate internal leakage, cooler fouling, or a relief valve issue.
Pressure is similar. A single pressure point tells part of the story. Pressure trend, stability, and comparison with known machine behaviour tell much more.
This video gives a useful visual overview of how condition monitoring methods support maintenance decisions in practice:
What doesn't work well
The weak approach is over-instrumentation. Adding sensors everywhere without a failure-mode review creates dashboards, not reliability. The strongest hydraulic programmes usually start with a short list of high-signal indicators on high-impact assets, then expand only when the first phase is producing actionable findings.
From Data Collection to Actionable Maintenance Triggers
Collecting readings is easy. Turning them into useful maintenance action is the hard part. Many teams have temperature logs, oil reports, or pressure readings already. The problem is that nobody has defined what change is significant, who gets alerted, and what task should follow.
An effective workflow for hydraulics should follow a measurable failure-mode chain. The most useful parameters commonly include oil cleanliness, differential pressure across filters, temperature stability, and vibration, and UK-relevant guidance also notes that hydraulic-system failures are often linked to contamination and weak maintenance controls, as summarised in MaintainX guidance that references HSE priorities.
Build the baseline first
A CBM alarm without a baseline is guesswork. Before setting limits, record what healthy operation looks like.
That baseline should include:
- Normal operating temperature at known load conditions
- Pressure and flow behaviour during standard duty
- Filter differential pressure after service and during stable running
- Oil cleanliness trend over time, not just one sample
- Pump or motor vibration trend at repeatable operating points
If you skip this step, you'll either miss faults or drown the team in nuisance alarms.
A threshold should answer a practical question: inspect, plan work, or stop the machine.
Warning and critical triggers
Hydraulic systems usually need more than one alarm level. A single hard shutdown point is too crude. The better pattern is staged response.
| Trigger level | Typical response |
|---|---|
| Warning | Inspect, verify load condition, check for leaks, review trend |
| Action required | Plan repair, stage parts, schedule intervention |
| Critical | Controlled shutdown or immediate escalation if safe operation is at risk |
That structure helps avoid alarm fatigue. If every slight change generates an urgent notification, technicians soon stop trusting the system. A threshold only has value when it consistently leads to the right action.
Make the reports usable
Raw data rarely changes behaviour on its own. Someone has to convert it into a trend that a fitter, supervisor, or planner can act on. That's why dashboards and reporting logic matter as much as the sensor itself.
For teams trying to improve how they summarise findings, this piece on improving data analysis and reports is a useful reminder that reporting should reduce ambiguity, not add another layer of noise.
On hydraulic assets, reports should stay close to the machine reality:
- Show trend direction, not just current value
- Link alarm to component, not just tag number
- State the likely failure mode
- Assign the next inspection or work step clearly
Where contamination control is a priority, regular particle counting for hydraulic oil condition gives one of the clearest routes from data to action because it ties directly to filtration, fluid health, and wear risk.
Integrating CBM with Your Existing Management Systems
A CBM setup becomes far more useful when it stops being a standalone monitoring island. Sensor data is helpful. Sensor data that automatically creates a task, assigns a person, and records what happened is where its true operational value shows up.
That doesn't mean every business needs a fully connected smart factory. In many UK SMEs, digital adoption is still uneven, so a staged rollout is more practical than a big-bang system replacement, as noted in Faraday Predictive's discussion of staged condition monitoring adoption.
The practical integration path
Most hydraulic CBM integrations follow one of these routes:
- Manual review plus CMMS entry for early-stage programmes
- Sensor to gateway to dashboard where alerts are reviewed before work orders are raised
- Direct integration into CMMS or EAM so threshold breaches generate tasks automatically
- Connection through PLC or existing controls where plant logic already captures part of the operating picture
For a small or mid-sized operation, the first or second route is often enough to prove value. You don't need a full software estate redesign to begin monitoring one critical power pack properly.
What a useful integration actually does
The point of integration isn't visualisation alone. It's workflow. When a hydraulic filter differential pressure alert appears, the system should make the next step obvious. That could mean creating an inspection task, checking whether the right filter element is in stores, or prompting a technician to inspect contamination sources before changing the element.
A good integrated setup should support:
| Need | Useful result |
|---|---|
| Alert handling | The right person sees the issue quickly |
| Work order generation | Inspection or repair is raised without delay |
| History tracking | Teams can compare faults, trends, and repeat failures |
| Parts planning | Stores can stage filters, seals, or replacement units in time |
Keep the first stage narrow
Retrofitting older hydraulic machinery can be awkward. Space is tight, wiring routes are limited, and operating environments are often dirty, wet, or remote. That's why staged adoption works well. Start with one failure mode on one critical asset. Prove that the measurement is reliable, the alert is meaningful, and the resulting task improves the outcome.
Then expand.
That sequence matters more than the sophistication of the hardware. A modest system that triggers the right work at the right time is better than an expensive architecture that nobody trusts enough to use.
Calculating Your Return on Investment and Learning from Scenarios
Most maintenance teams already know a hydraulic failure is costly. The challenge is turning that into a business case that operations and finance will support. The cleanest way to do it is to compare monitoring cost against avoidable failure cost.
Industry guidance suggests CBM typically reduces maintenance costs by 25-35% and improves reliability by identifying degradation weeks or months before failure, according to Oxmaint's asset management overview. The same guidance also warns against over-instrumentation, which is why ROI tends to be strongest when you start with high-signal indicators such as oil particle count, pressure pulsation, and temperature drift.
A simple ROI view in pounds
You don't need a complex spreadsheet to make the first decision. Use a practical model:
Estimated annual return = avoided emergency repairs + avoided downtime cost + reduced unnecessary routine work – annual monitoring cost
The exact pounds will differ by site, but the structure is usually clear.
For example, imagine a UK manufacturer running several hydraulic presses. One press suffers recurring faults around pump wear and contamination. Under reactive maintenance, the team pays for urgent labour, expedited parts, production disruption, and follow-on clean-up in the circuit. Under a focused CBM approach, the business monitors contamination trend, pressure behaviour, and temperature stability on that press and intervenes before the fault becomes a full stoppage.
What changes in the scenario
Before CBM, the pattern often looks like this:
- Fault reported by operator after visible performance drop
- Maintenance team starts diagnosis under pressure
- Damage has already spread beyond the first failed component
- Planned work is displaced by urgent repair
After CBM, the pattern is different:
- Trend indicates deterioration before failure
- Team inspects during a controlled window
- Parts are staged before intervention
- Repair is smaller because secondary damage hasn't spread
The best ROI usually comes from preventing one ugly failure on one important machine, not from trying to digitise the whole site at once.
Where teams miscalculate
The common mistake is to count only the cost of the sensor and ignore the cost of doing nothing. Another is to monitor too broadly from day one. If you fit sensors to every hydraulic asset, the overhead can outrun the benefit.
A stronger business case usually focuses on one or two scenarios:
- A critical power pack that stops production
- A mobile machine where downtime causes contract or site disruption
- A contamination-prone hydraulic circuit with repeat valve or pump damage
In each case, the value comes from catching measurable deterioration early enough to plan the work. That's the point where condition based maintenance stops being a technical idea and becomes a financial one.
Your Hydraulic CBM Implementation Checklist and Next Steps
A workable CBM programme doesn't need to be huge. It needs to be disciplined. Start with the assets that matter, monitor the variables that move first, and define the action that follows when the reading changes.

A practical checklist
- Choose critical hydraulic assets with clear operational consequence if they fail.
- Define failure modes before selecting hardware. Pumps, filters, valves, seals, and cooling faults each need different signals.
- Pick a small monitoring set built around high-value indicators rather than blanket instrumentation.
- Capture healthy baseline data under repeatable operating conditions.
- Set warning and critical thresholds that lead to specific actions.
- Connect alerts to your maintenance process so someone owns the response.
- Train technicians and operators to recognise what the readings mean on the actual machine.
- Pilot first, then expand once the first asset proves its value.
- Review false alarms and missed alarms and adjust limits accordingly.
- Measure business impact in avoided disruption, cleaner planning, and lower repair burden.
What success usually looks like
The strongest hydraulic CBM programmes aren't flashy. They're consistent. The readings are trusted, the alarms are few but meaningful, and the team knows the difference between a monitor point and a maintenance trigger.
If your current approach still relies on waiting for noise, heat, or performance loss to become obvious, there's room to improve. For many UK businesses, the right next step isn't a complete digital overhaul. It's one well-chosen hydraulic asset, one known failure mode, and one monitoring method that gives the team enough warning to act properly.
If you want help selecting components, monitoring points, or a practical route into hydraulic condition based maintenance, contact MA Hydraulics Ltd. The team can support hydraulic system planning, component selection, and reliable solutions for mobile and industrial equipment. Phone 01724 279508 today, or send us a message.
